This post is my writeup of a talk I gave at Lambda World 2024 functional programming conference.
intro
How might we evolve published APIs safely and with minimal impact to the interface’s consumers?
This post introduces the Parallel Change approach, and explores its use at Artificial to safely introduce backward-incompatible changes in its REST API built in Haskell.
Parallel Change is an approach to refactoring or changing an interface which splits the introduction of backwards-incompatible change into three phases:
- expand: introduce the new version in parallel with the old version.
- migrate: clients move from the old version to the new.
- contract: once all clients have migrated, remove the old version from the interface.
Let’s look at a motivating example using a simplified version of Artificial’s API, which provides information about insurance policies as part of Artificial’s algorithmic underwriting product. This simplified API has two operations which allow us to get a single policy, or a collection of policies.
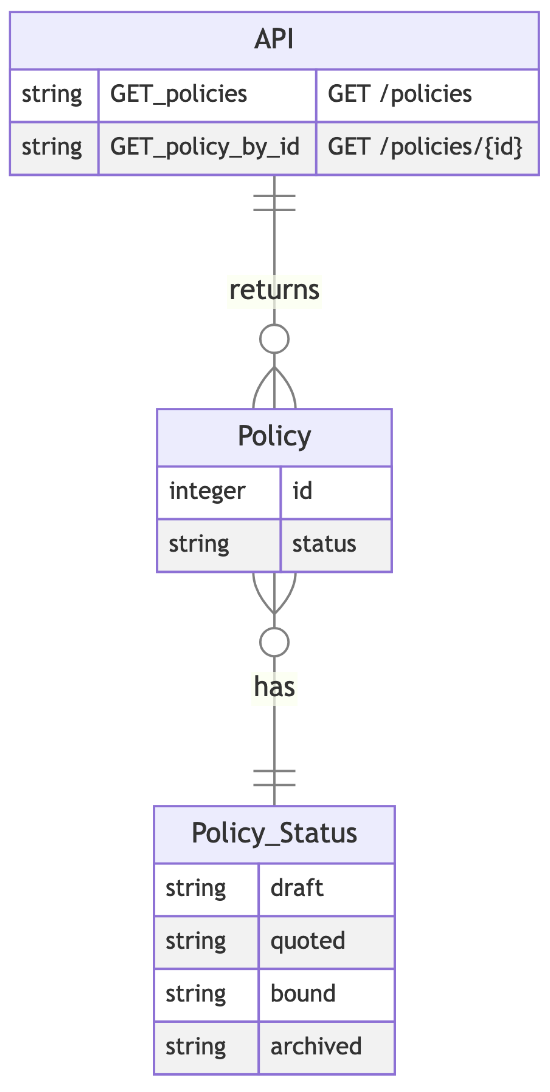 Here’s an OpenAPI specification for the same API:
Here’s an OpenAPI specification for the same API:
openapi: 3.0.0
info:
title: Artificial API
description: Retrieve information about insurance policies
version: 1.0.0
servers:
- url: https://api.artificial.io
paths:
/policies:
get:
description: Retrieve a list of policies
responses:
'200':
description: A list of policies
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Policy'
tags:
- policies
/policies/{id}:
get:
description: Retrieve a specific policy by its ID
parameters:
- name: id
in: path
required: true
description: An integer id
schema:
type: integer
example: 12345
responses:
'200':
description: Details of the specified policy
content:
application/json:
schema:
$ref: '#/components/schemas/Policy'
tags:
- policies
components:
schemas:
Policy:
type: object
description: An instance of an insurance policy
properties:
id:
description: The policy identifier
type: integer
example: 12345
status:
description: A label to describe where a given policy is in its lifecycle
type: string
enum:
- draft
- quoted
- bound
- archived
example: bound
required:
- id
- status
the problem
Imagine we’d like to change the schema to use NanoIDs, rather than integer IDs. NanoIDs have a lower chance of collisions and present a nicer experience in URLs versus UUIDs.
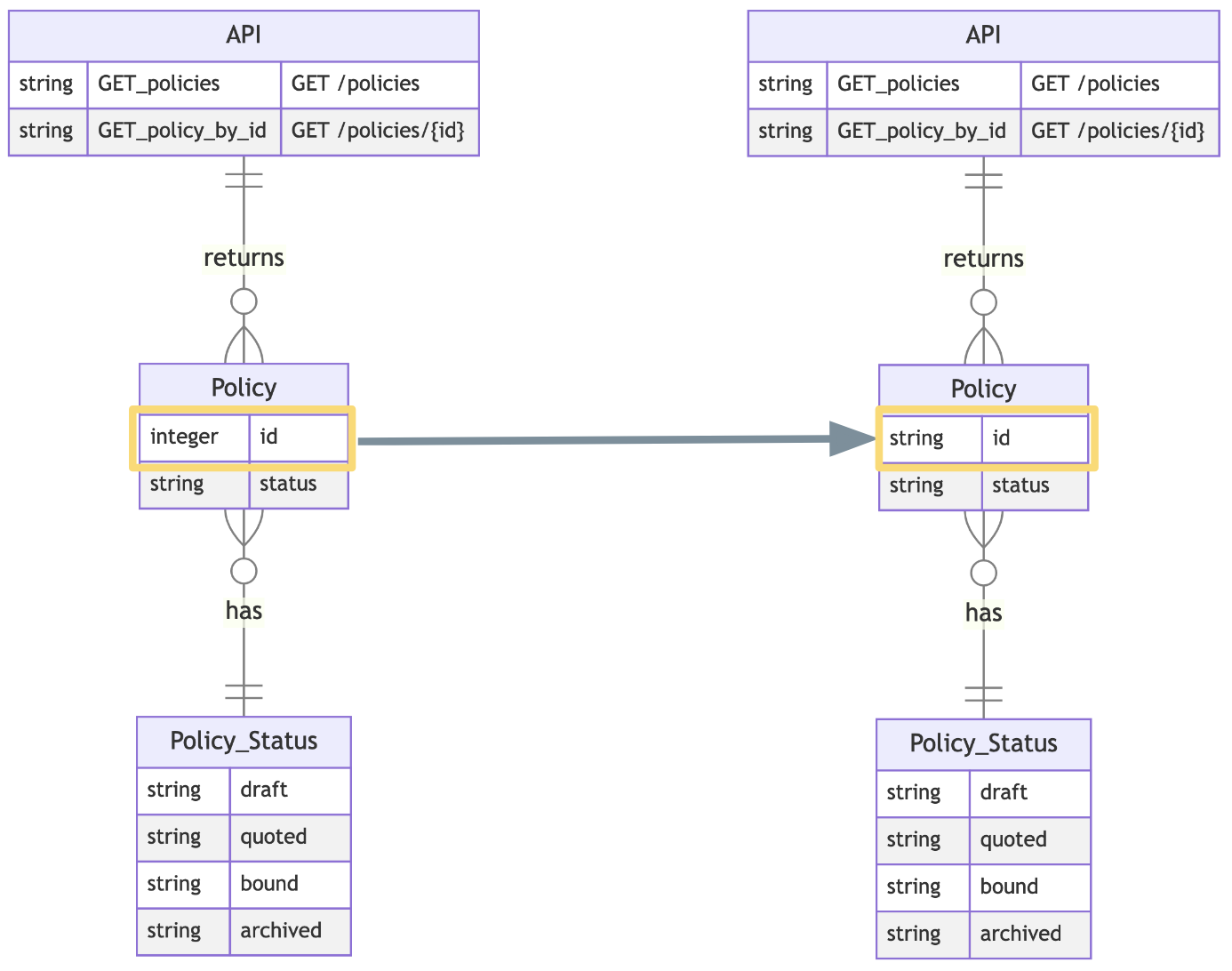
So we’re replacing string IDs, e.g. 12345 with NanoIDs e.g. policy_xyz. Here’s the change expressed as a diff on the HTTP request and response:
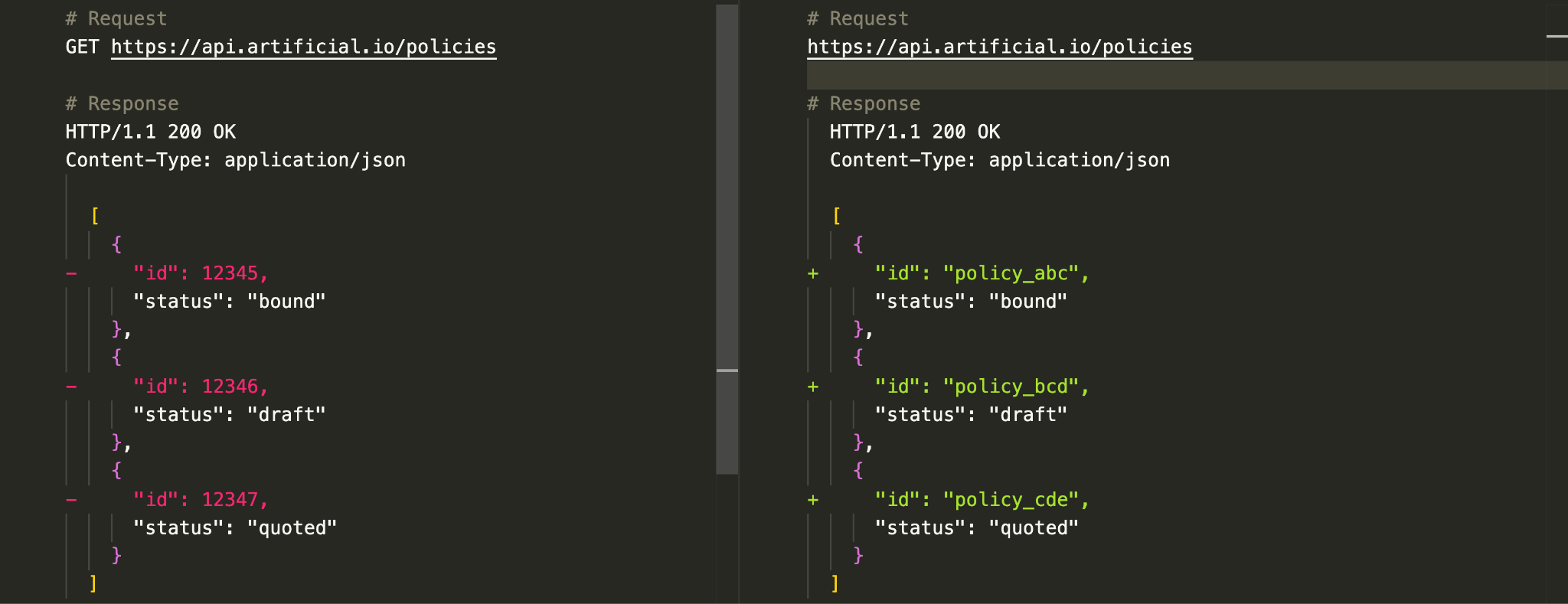
This illustrates a breaking change, because we’ve changed the API in a way that forces clients to adapt to the altered response.
Our goal as designers of this API is to provide a working, easy-to-use, unsurprising interface. Changes or new functionality should be introduced with minimal impact to the consumers of the API. This means we:
- avoid introducing breaking changes
- provide a smooth migration path from the old to new behaviour
backwards-compatibility and breaking change
Backwards-incompatible changes are inevitable in any real-world interface, but breaking changes are not.
In the context of APIs, a change is backwards-incompatible is when:
- the API requires more, e.g.
- adding a new validation rule to an existing resource
- adding a new required parameter
- making a previously optional parameter required
- the API provides less, e.g.
- removing an entire operation
- removing a field in the response
- removing enum values
- the API changes in some user-visible way, e.g.
- changing the path of an endpoint
- changing the type of a parameter or response field
- changing authentication or authorisation requirements
Any change that causes a previously valid request to become invalid is a breaking change.
Backwards-incompatible changes become breaking changes when they are applied by default and force the consumer to alter their behaviour.
solution options
What options do we have to release backwards-incompatible changes?
- Version the API
- Version the operation
- Make a Parallel Change
These options are not exhaustive, but illustrate approaches at increasing levels of granularity.
version the API
One option is to release the change behind an entirely new API version. Common versioning approaches at this level include:
- Different base paths (e.g.,
/v1/,/v2/) - Query parameters (e.g.,
?version=1) - Custom headers (e.g.,
Version: 1)
Let’s version the base path and look at how the request/response changes:
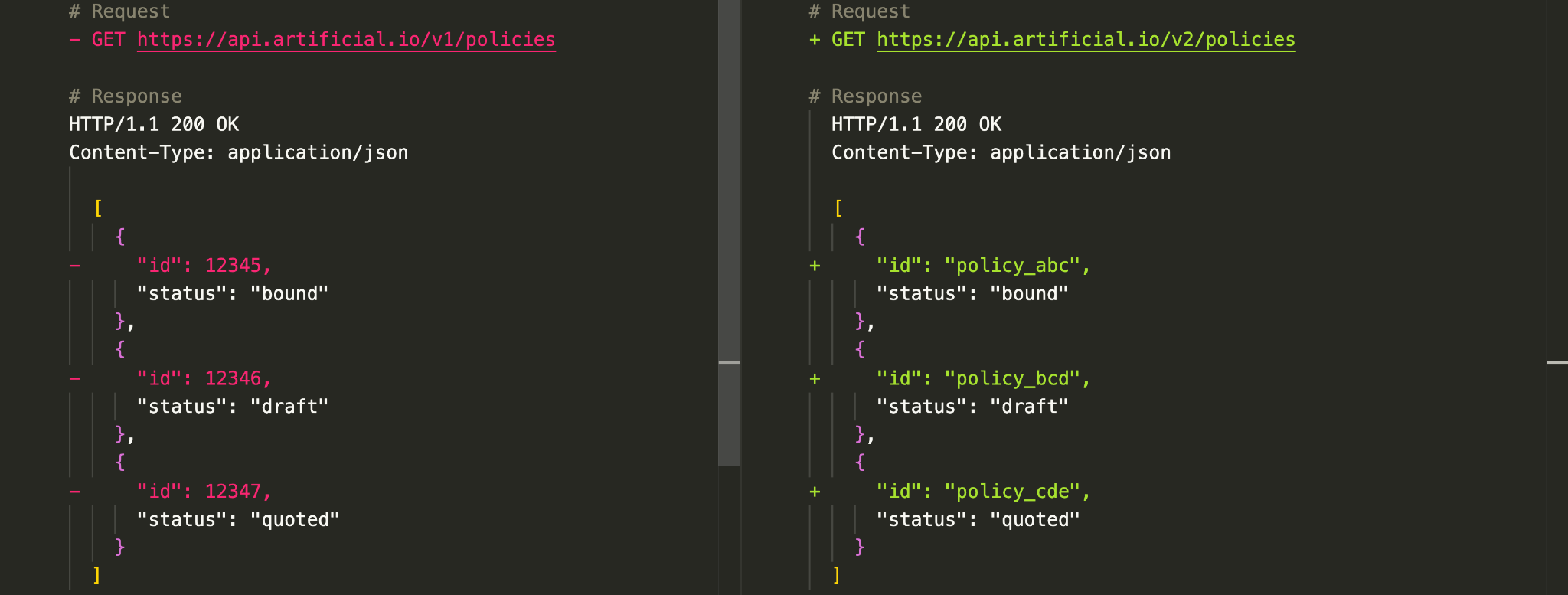
In this example:
- The original
/v1endpoint is unchanged, allowing clients to migrate at their own pace. - We’ve introduced a new
/v2path for the updated endpoint.
This style of versioning is typically used for significant API changes. A more granular approach like versioning individual operations may be more suitable for our example use case.
version the operation
A more flexible approach is to version individual operations using standard HTTP headers. This allows for finer-grained control over versioning.
Here’s what versioned operations might look like for the client:
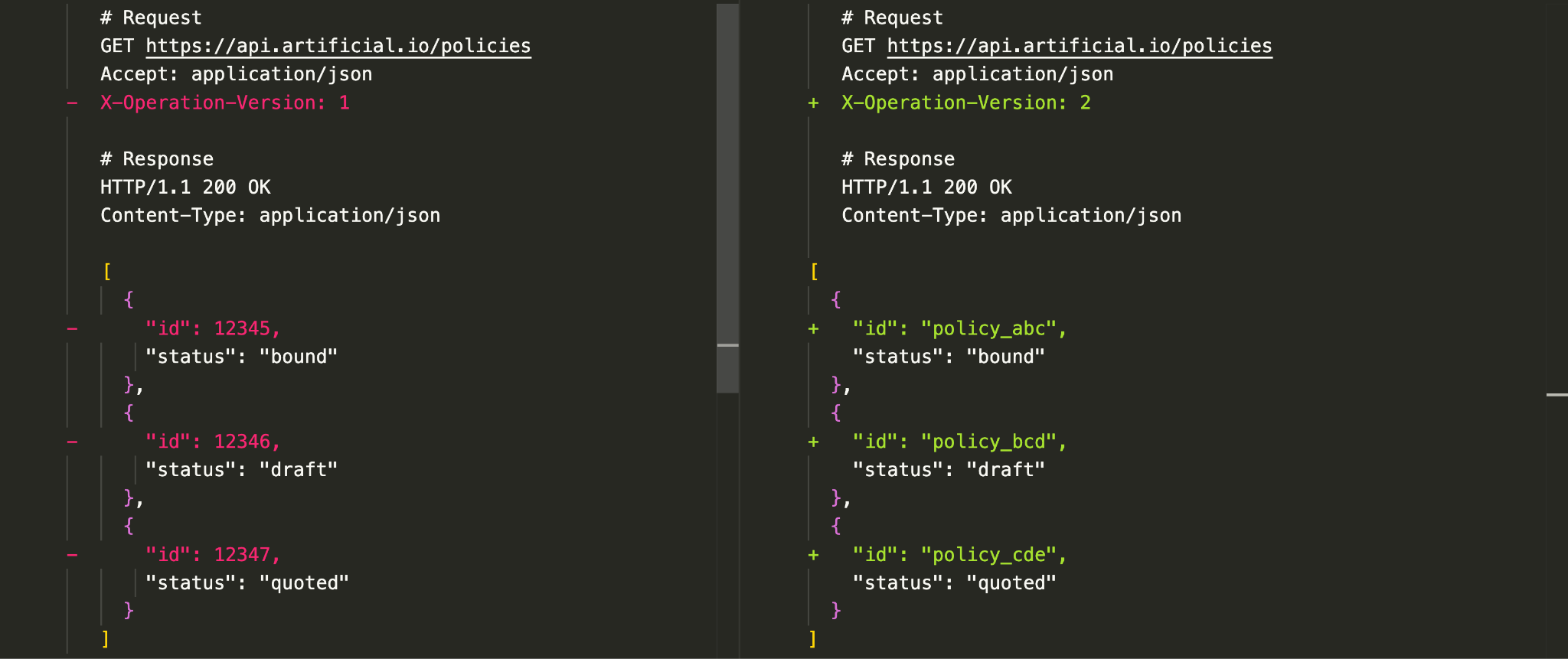
In this example:
- We’ve kept the same endpoint path.
- We define two versions of the Policy schema in the API implementation.
- Clients can request the Policy version they want using a custom
Operation-Versionheader:
The API handles the requests differently in code depending on the value of the header:
- when the Header is
X-Operation-Version: 1, returnsPolicyV1with an integer ID - when the Header is
X-Operation-Version: 2, returnsPolicyV2with nanoID for V2
This approach offers more flexibility than full API versioning, but we still expect the client to compare and switch between versions. HTTP headers can also introduce complications with client-side caching, which we’d like to avoid if we can. Which brings us to our final option: the Parallel Change approach.
make a Parallel Change
How might we transform breaking changes into non-breaking ones, without the overhead of multiple API versions? The Parallel Change approach suggests we add new capabilities alongside the old, and deprecate the old ones when they’re no longer in use. We do so in three phases:
- expand: introduce the new version in parallel with the old version.
- migrate: clients move from the old version to the new.
- contract: once all clients have migrated, remove the old version from the interface.
Here’s how the Parallel Change approach might look from the API consumer’s perspective:
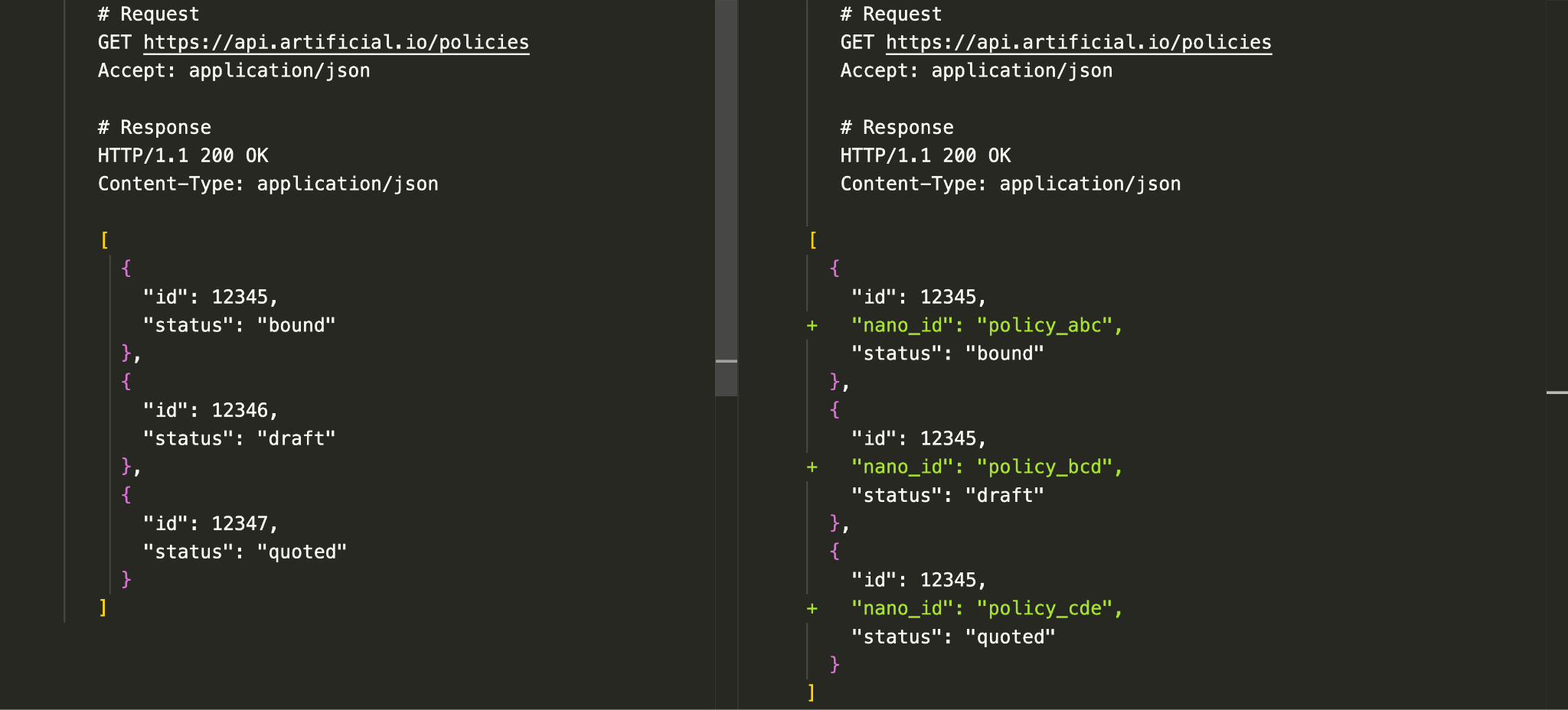
This change is small and purely additive compared to the previous approaches. So we don’t:
- remove a field from the response
- change the field’s type or semantics
- require the consumer to change their behaviour
This accretive approach is the essence of turning breaking change into non-breaking API evolution. It reduces the migration risk and effort for the API consumer; adopting or reverting a new capability is as simple accessing a different field in the response payload for the same request rather than switching to a new version.
However, this approach increases the burden on the API producer; it’s more work to maintain multiple code paths, there’s a risk of slower client migration, and it requires more effort to monitor usage and deprecate unused capabilities.
How might we mitigate some of the downsides of the Parallel Change approach?
parallel change at Artificial
Here are a few things we’ve learned, using Parallel Change to evolve an external client-facing API at Artificial.
object types in schema simplify API growth
At the expand phase, we change the interface to support both old and new capabilities.
Defaulting to JSON object types in the response made it easier to evolve the API in a backwards-compatible way. Objects allow us to add new fields without removing older ones and facilitate non-breaking change.
For example, introducing pagination to our example schema is a substantial breaking change, as we change the root schema from an array to an object:
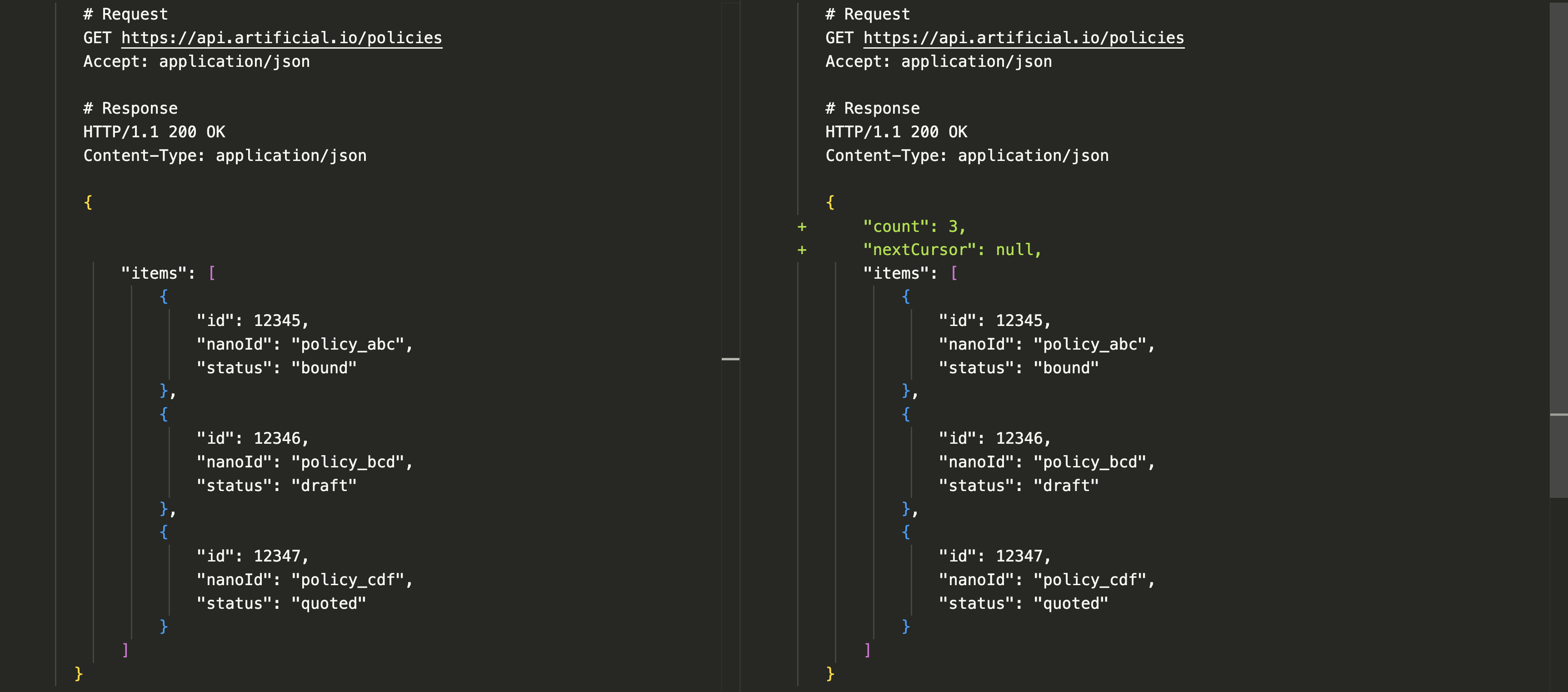
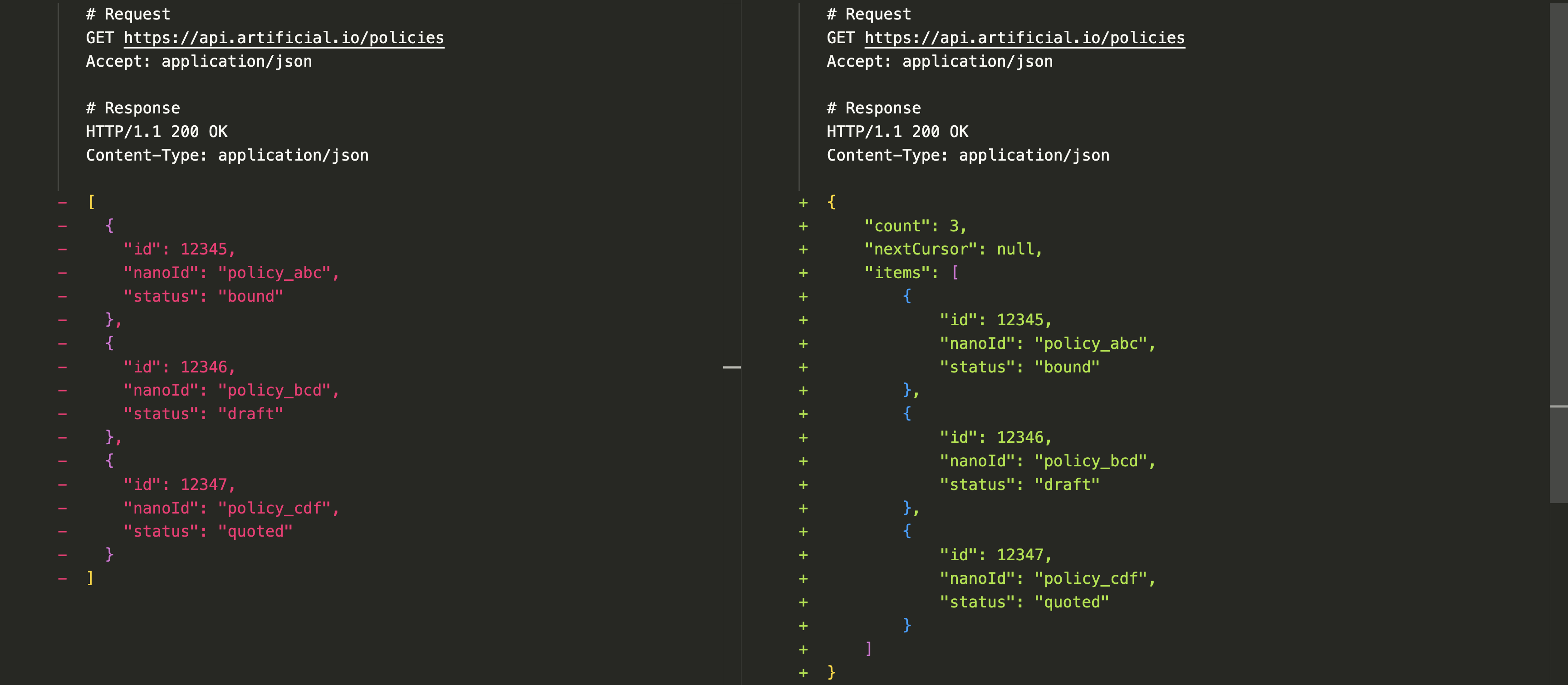 Whereas designing our schema upfront by wrapping arrays in objects gives us flexibility for future non-breaking additions:
Whereas designing our schema upfront by wrapping arrays in objects gives us flexibility for future non-breaking additions:
deprecation flags and API documentation encourage migration
At the migrate phase, we update clients from the old to new capabilities. A successful migration phase relies on clear communication with clients, and we can use documentation and other async communication tools to help.
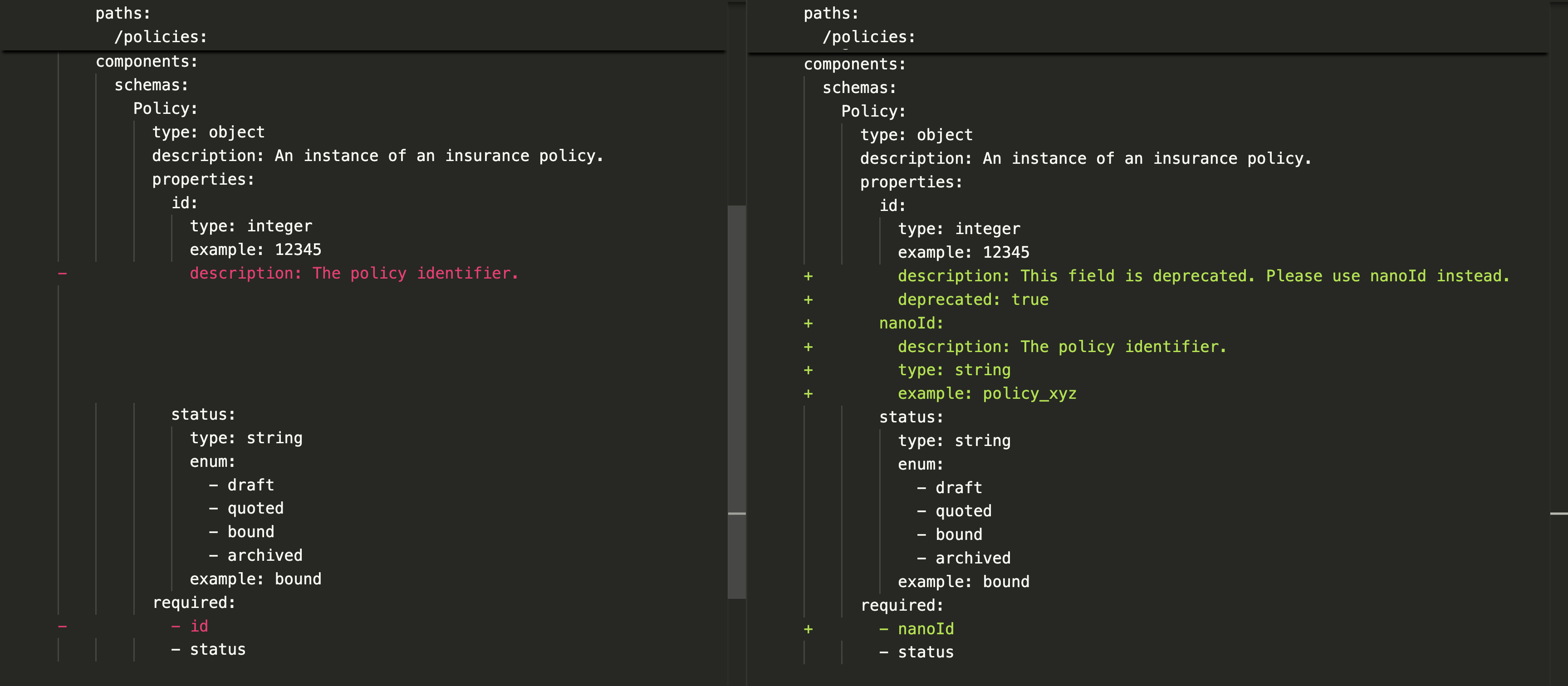
For example, we generate API documentation in the OpenAPI specification format, using the deprecation field and schema docs to point to the newer capabilities and encourage migration. Here’s an example of how the id → nanoId change would be reflected in the OpenAPI spec as a diff:
telemetry tools help with sunsetting
In the contract phase, we sunset the old capability once it’s no longer used; removing it from the interface and deleting its artefacts such as code, configuration and documentation.
We collect telemetry data to understand API usage and identify capabilities that are no longer used and could be sunset. Currently, our observability tools of choice include BetterStack, OpenTelemetry, and Grafana.
summary
At a high level, Parallel Change is an approach to refactoring or changing an interface which splits the introduction of breaking change into expand, migrate and contract phases.
The overall goal is to evolve the system in a way that minimises the impact on those consuming the interface. We do this by making improvements in small, additive-only increments know as accretion.
The downside of this approach is that it can be more work for API producer to maintain, migrate and monitor the parallel changes. However there are ways of mitigating this extra work at each phase, for example:
- At the expand phase, we can make API evolution easier by defaulting to object types in the schema.
- At the migrate phase, by generating clear documentation which highlights deprecated parts of the API.
- At the contract phase, with telemetry that points out where we can sunset unused capabilities.
further reading
This post is a summary of some things we’ve learned from a recent application of old ideas. Shared with thanks in particular to the following sources: